 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergistic saliency and depth prediction for RGB-D saliency detection
Jul 03, 2020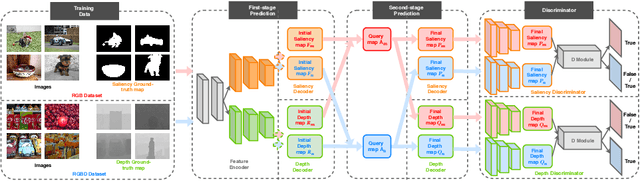
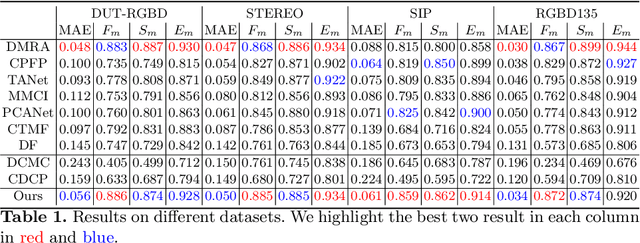
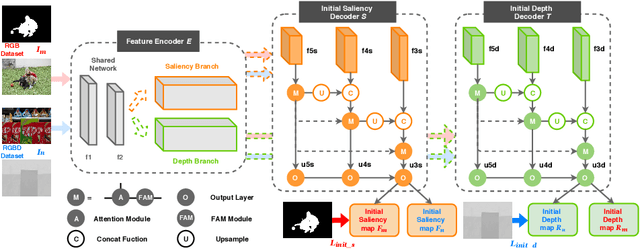
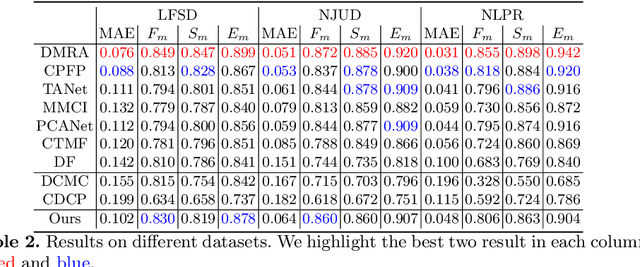
Depth information available from an RGB-D camera can be useful in segmenting salient objects when figure/ground cues from RGB channels are weak. This has motivated the development of several RGB-D saliency datasets and algorithms that use all four channels of the RGB-D data for both training and inference. Unfortunately, existing RGB-D saliency datasets are small, leading to overfitting and poor generalization. Here we demonstrate a system for RGB-D saliency detection that makes effective joint use of large RGB saliency datasets with hand-labelled saliency ground truth together, and smaller RGB-D saliency datasets {\em without} saliency ground truth. This novel prediction-guided cross-refinement network is trained to jointly estimate both saliency and depth, allowing mutual refinement between feature representations tuned for the two respective tasks. An adversarial stage resolves domain shift between RGB and RGB-D saliency datasets, allowing representations for saliency and depth estimation to be aligned on either. Critically, our system does not require saliency ground-truth for the RGB-D datasets, making it easier to expand these datasets for training, and does not require the D channel for inference, allowing the method to be used for the much broader range of applications where only RGB data are available. Evaluation on seven RGBD datasets demonstrates that, without using hand-labelled saliency ground truth for RGB-D datasets and using only the RGB channels of these datasets at inference, our system achieves performance that is comparable to state-of-the-art methods that use hand-labelled saliency maps for RGB-D data at training and use the depth channels of these datasets at inference.
When Relation Networks meet GANs: Relation GANs with Triplet Loss
Mar 17, 2020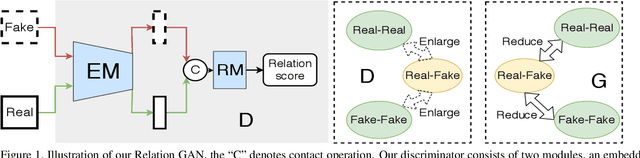
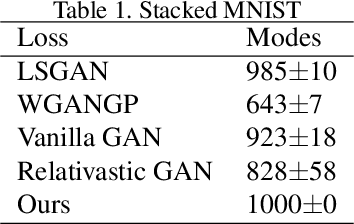
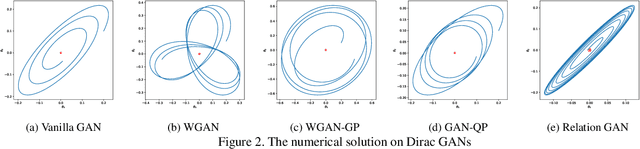
Though recent research has achieved remarkable progress in generating realistic images with generative adversarial networks (GANs), the lack of training stability is still a lingering concern of most GANs, especially on high-resolution inputs and complex datasets. Since the randomly generated distribution can hardly overlap with the real distribution, training GANs often suffers from the gradient vanishing problem. A number of approaches have been proposed to address this issue by constraining the discriminator's capabilities using empirical techniques, like weight clipping, gradient penalty, spectral normalization etc. In this paper, we provide a more principled approach as an alternative solution to this issue. Instead of training the discriminator to distinguish real and fake input samples, we investigate the relationship between paired samples by training the discriminator to separate paired samples from the same distribution and those from different distributions. To this end, we explore a relation network architecture for the discriminator and design a triplet loss which performs better generalization and stability. Extensive experiments on benchmark datasets show that the proposed relation discriminator and new loss can provide significant improvement on variable vision tasks including unconditional and conditional image generation and image translation.
Class-Conditional Domain Adaptation on Semantic Segmentation
Nov 28, 2019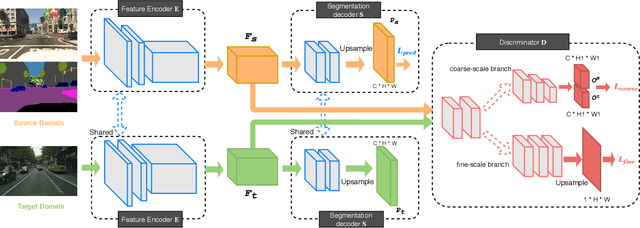
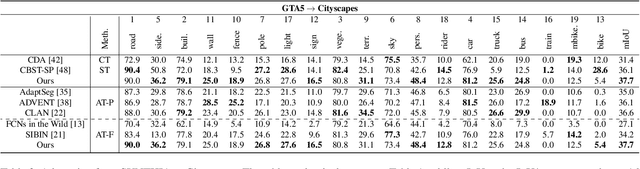
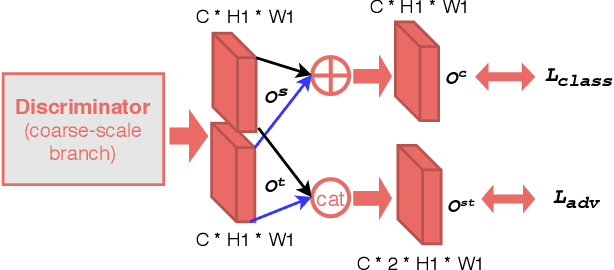
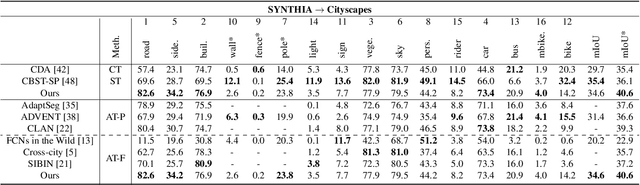
Semantic segmentation is an important sub-task for many applications, but pixel-level ground truth labeling is costly and there is a tendency to overfit the training data, limiting generalization. Unsupervised domain adaptation can potentially address these problems, allowing systems trained on labelled datasets from one or more source domains (including less expensive synthetic domains) to be adapted to novel target domains. The conventional approach is to automatically align the representational distributions of source and target domains. One limitation of this approach is that it tends to disadvantage lower probability classes. We address this problem by introducing a Class-Conditional Domain Adaptation method (CCDA). It includes a class-conditional multi-scale discriminator and the class-conditional loss. This novel CCDA method encourages the network to shift the domain in a class-conditional manner, and it equalizes loss over classes. We evaluate our CCDA method on two transfer tasks and demonstrate performance comparable to state-of-the-art methods.